



Inventario de Proxmox con n8n
Cuando montas un clúster Proxmox pequeño, más o menos te apañas de memoria. Sabes qué nodo tiene más carga, dónde está la VM de pruebas, qué contenedores siguen vivos desde hace meses y qué storage anda más justo. El problema empieza cuando el entorno crece un poco. De repente ya no tienes dos o tres máquinas, sino varias VMs, varios LXC, snapshots que se han quedado ahí “por si acaso”, backups en otro lado y una red que, sobre el papel, parecía clarísima pero en la práctica ya no tanto.
Ahí es donde montar un inventario deja de ser una manía de administrador ordenado y pasa a ser algo útil de verdad. Y si lo haces con n8n, mejor todavía, porque no te limitas a sacar una lista estática, montas un proceso automático que consulta Proxmox, recoge los datos, los normaliza y te deja una visión bastante completa del clúster. n8n encaja muy bien para esto porque sus nodos más importantes para este caso son precisamente HTTP Request, Schedule Trigger y Code, es decir, pedir datos a APIs, ejecutar el flujo por horario y transformar la información antes de guardarla o enviarla a otro sistema.
La idea de esta guía no es vender humo ni hablar en abstracto. La idea es explicarte, en lenguaje normal, cómo plantear un inventario de un clúster Proxmox con n8n de forma seria, qué piezas necesitas y qué puedes esperar realmente del resultado. Porque sí, puedes sacar muchísima información de Proxmox por API, pero conviene tener claro desde el principio qué parte es dato directo y qué parte es inferencia. Proxmox VE documenta su API oficial como una API tipo REST con JSON como formato principal, y el API Viewer expone rutas para cluster, nodes, storage, QEMU y LXC, que es justo lo que necesitamos para un inventario de infraestructura.
Qué vamos a entender por “inventario”
Cuando digo inventario, no me refiero a una tabla con nombres y poco más.
Un inventario útil de un clúster Proxmox debería permitirte responder preguntas bastante concretas, qué nodos existen, qué VMs y contenedores LXC hay, en qué nodo corre cada uno, qué recursos consumen, qué almacenamiento usan, qué snapshots tienen, si cuentan con backups y a qué red o bridge están conectados. El API Viewer de Proxmox expone precisamente el árbol de recursos que permite navegar por esos objetos, y el endpoint de cluster resources es una buena puerta de entrada porque agrupa buena parte de la visión general del clúster.
Esa es la primera idea importante, no empieces por pensar en dashboards bonitos ni en automatizaciones muy vistosas. Empieza por responder bien a una pregunta básica: “¿qué hay en mi clúster y cómo se relaciona?”.
La arquitectura mínima que necesitas
Para montar esto con sentido, lo normal es apoyarte en cuatro piezas.
- La primera es n8n, que ejecutará el workflow y hará las llamadas a la API.
- La segunda es la API de Proxmox VE, que te dará la información del clúster, nodos, storage, máquinas virtuales y contenedores.
- La tercera, opcional pero muy recomendable, es Proxmox Backup Server, si quieres enriquecer el inventario con datos reales de copias de seguridad.
- Y la cuarta es una base de datos, normalmente PostgreSQL, para guardar los resultados y poder consultar histórico, diferencias y hallazgos. n8n documenta tanto el nodo HTTP Request como el de Postgres, y Proxmox documenta por separado la API de VE y la API de PBS.
La autenticación contra Proxmox
Lo correcto aquí es usar API tokens, no usuario y contraseña pegados sin más en un nodo. Proxmox VE documenta explícitamente el uso de tokens dentro de su API, y PBS hace lo mismo con sus propios tokens y permisos. Eso te permite crear una cuenta técnica con permisos de solo lectura para inventario, que es exactamente lo que necesitas en este proyecto.
En n8n, lo más limpio es crear una credencial reutilizable para el nodo HTTP Request. Si estás atacando Proxmox VE, la base URL suele ser algo como:
https://tu-proxmox:8006/api2/json

Y la cabecera de autorización se monta con el token de Proxmox. A partir de ahí, todos los nodos HTTP Request del workflow usan esa misma credencial.
Configuración Infraestructura Proxmox
Explicamos como Instalar n8n vía Docker Compose, y vamos a dar por sentado que n8n está corriendo y funcionando.
A continuación, definimos los pasos necesarios:
Preparar accesos entre n8n y Proxmox
Crea un usuario técnico o token de solo lectura en Proxmox VE para consultar la API (hay que evitar usar un usuario administrador).
Proxmox VE usa una API tipo REST con JSON y documenta el árbol de recursos en su API Viewer. Si además quieres inventariar backups reales, prepara también un token de Proxmox Backup Server, que expone su propia Management API y API Viewer.
Accedemos a Datacenter -> Permissions -> Users -> Add:
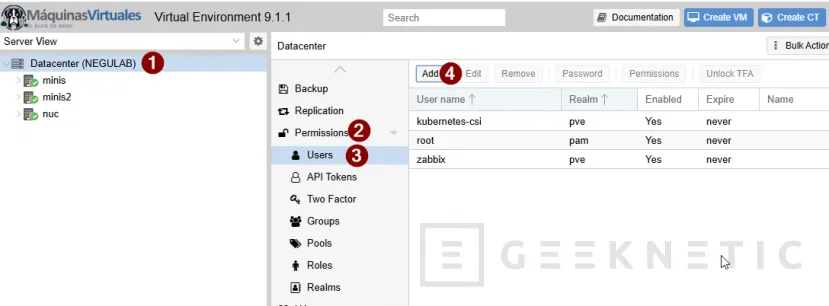
Ahora rellena estos campos:
- User name: por ejemplo
n8n-inventory - Realm: normalmente
pve - Password: una contraseña larga
- Confirm password
- Puedes dejar nombre y apellidos vacíos si es un usuario técnico
Pulsa ADD para guardar.
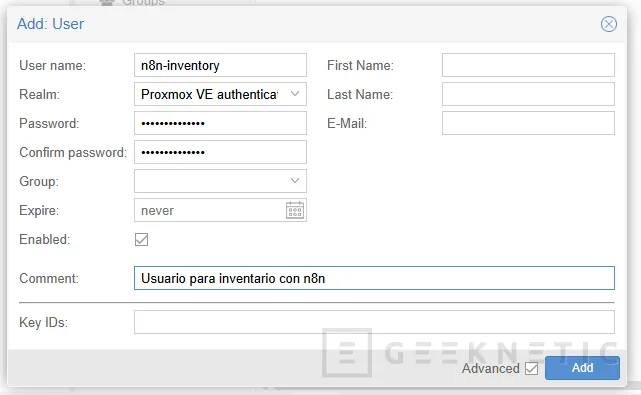
El identificador final del usuario será algo como (el "@pve" al final es importante):
n8n-inventory@pve
Crea un API Token para ese usuario
Ahora no vas a usar la contraseña en n8n. Vas a crear un API Token, que es lo recomendado para accesos automáticos y no interactivos. Proxmox VE documenta autenticación por ticket o por token, y PBS recomienda también tokens para usos no interactivos.
En Proxmox VE:
- Vuelve a Datacenter > Permissions > API Tokens
- Pulsa Add
- En User selecciona
n8n-inventory@pve - En Token ID escribe algo claro, por ejemplo:
inventory
- Puedes poner expiración o dejarlo sin fecha si es un entorno interno controlado
- Pulsa Add
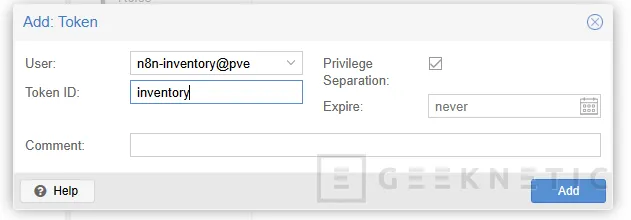
Cuando lo guardes, Proxmox te mostrará el secret del token. Ese secreto lo debes copiar y guardar en un gestor seguro, porque luego no siempre se vuelve a mostrar.
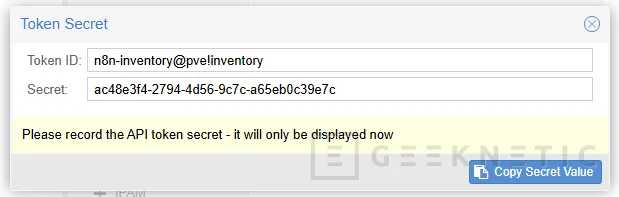
Con eso ya tienes dos piezas:
- Token ID completo:
n8n-inventory@pve!inventory
- Token secret:
Una cadena larga que te da Proxmox
Ese signo "!" también importa. El formato del token en Proxmox VE es usuario + realm + nombre del token.
Dale permisos mínimos al usuario o al token
Crear el usuario no basta. Si no le das permisos, la API responderá con errores de autorización.
En Proxmox, los permisos se asignan en Permissions y se aplican sobre rutas o paths del árbol de objetos. La propia administración de Proxmox documenta permisos y ACLs en el área de gestión.
Para un inventario básico, lo habitual es dar permisos de lectura sobre el árbol principal del datacenter.
En la interfaz:
- Ve a Datacenter > Permissions
- Entra en Add > User Permission o API Token Permission
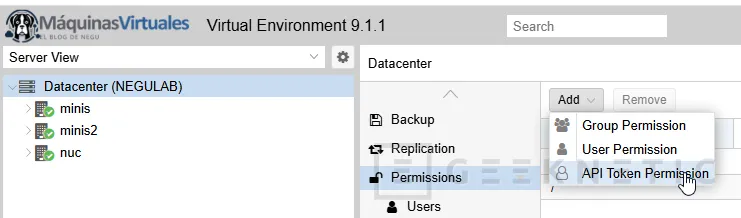
- Selecciona como Path "/"
- Selecciona el usuario
n8n-inventory@pveo directamente el token - Marca Propagate
- En el Role, usa un rol de solo lectura si te encaja con tu política interna (Ejemplo: PVEAuditor)
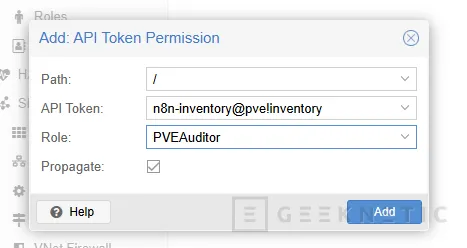
La parte importante aquí es esta: no des permisos de administrador total si solo vas a inventariar.
Comprueba que la API responde antes de tocar n8n
Antes de abrir n8n, comprueba que el token funciona.
Haz una prueba con curl desde tu ordenador o servidor:
curl -k -H "Authorization: PVEAPIToken=n8n-inventory@pve!inventory=TU_TOKEN_SECRET" \
https://TU_PROXMOX:8006/api2/json/cluster/resources
Si todo va bien, Proxmox devolverá JSON con recursos del clúster. Proxmox VE documenta ese formato de autenticación por token y la ruta de la API bajo /api2/json.
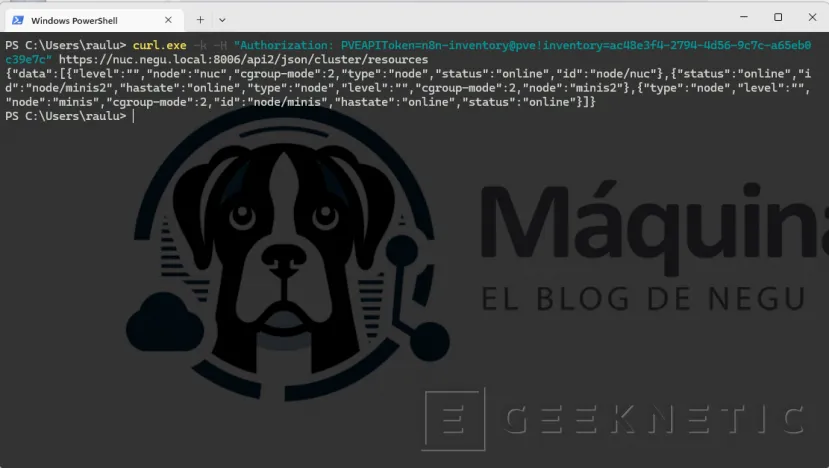
Si te devuelve error 401 o 403:
- El token está mal copiado
- No tiene permisos
- O estás usando mal el nombre completo del token.
Configuración n8n
Cuando abras n8n, quédate con estas tres ideas:
- Workflow: el flujo completo
- Node: cada bloque del flujo
- Credential: donde guardas accesos y secretos
La librería de credenciales y la documentación de nodos de n8n explican precisamente cómo autenticar HTTP Request y Postgres.
Tu trabajo aquí va a consistir en:
- Crear una credencial para Proxmox
- Crear una credencial para PostgreSQL
- Montar un workflow con nodos
Crea la credencial HTTP para Proxmox en n8n
En n8n:
- Ve a tu Workflow o genera uno nuevo:
- Añade un nodo HTTP Request
- Ábrelo
- En el campo Authentication, selecciona "Generic Credential Type". La documentación oficial de n8n indica que el nodo HTTP Request soporta varios métodos genéricos de autenticación, entre ellos Header auth, que es justo el que necesitamos para Proxmox.
- Después, en el tipo de credencial genérica, elige "Header Auth". La librería oficial de credenciales de n8n explica que Header auth se usa cuando el servicio autentica mediante una cabecera HTTP, indicando exactamente dos campos: el nombre de la cabecera y su valor.
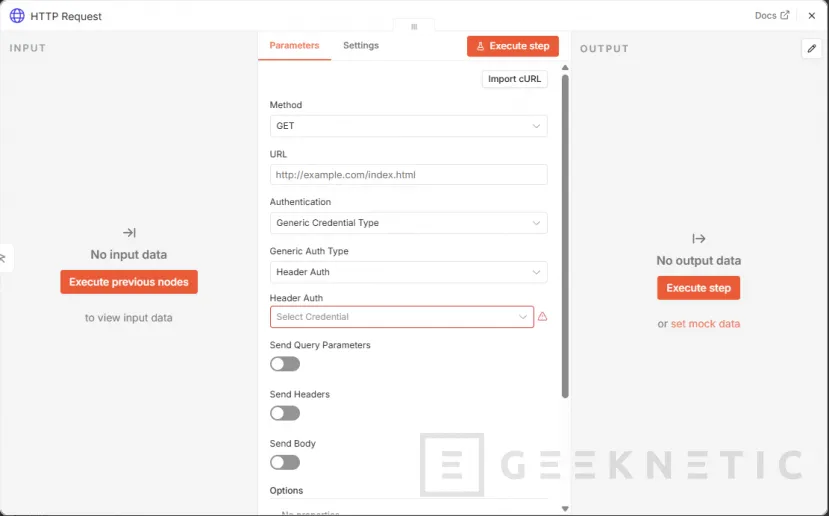
- Pulsa Create New Credential. Rellénalo así:
- Name: Proxmox VE API
- Header Name: Authorization
- Header Value: PVEAPIToken=n8n-inventory@pve!inventory=TU_TOKEN_SECRET
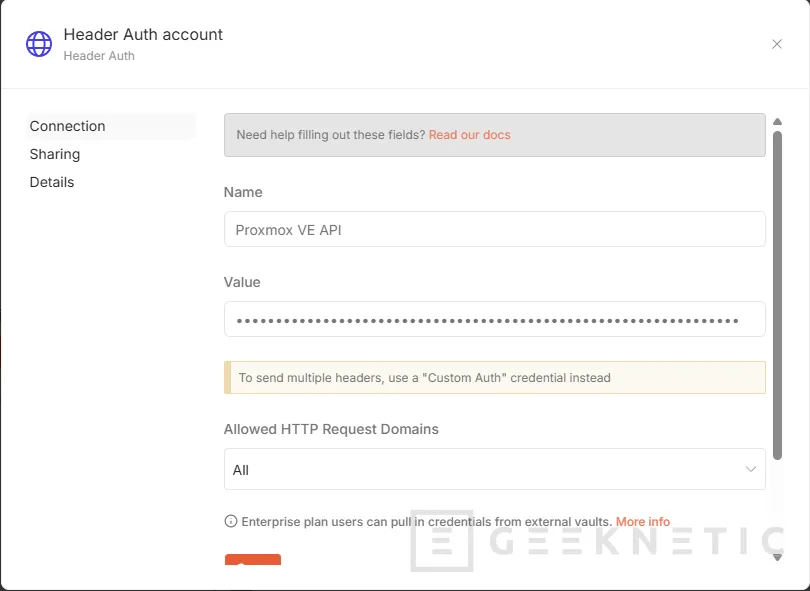
- Guarda la credencial.
- Agregamos la URL de nuestro nodo "https://IP-PROXMOX:8006/api2/json/cluster/resources"
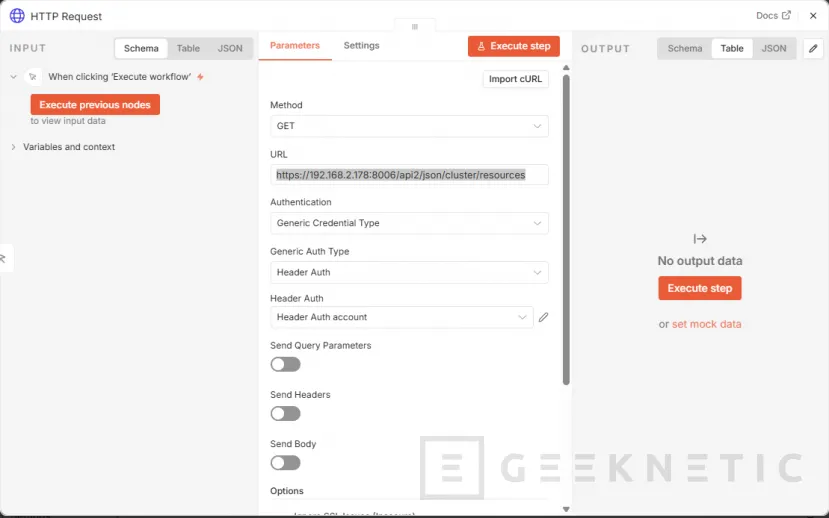
- Si no tenéis un certificado válido, os dará un error, así que podéis agregar la opción "Ignore SSL Issues (Insecure)" para hacer la validación, antes de agregarlo:
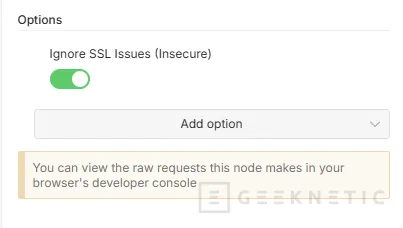
- Pulsamos Execute step para validar, debería darnos resultados si está todo correcto:
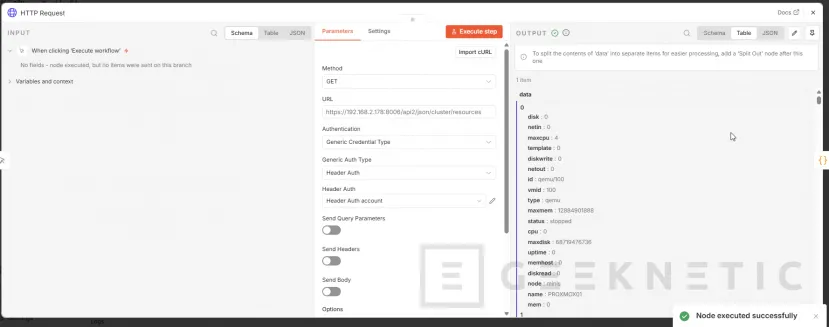
- Con esto ya hemos validado la conexión entre N8N y nuestro clúster Proxmox, ahora necesitamos separar los recursos a monitorizar:
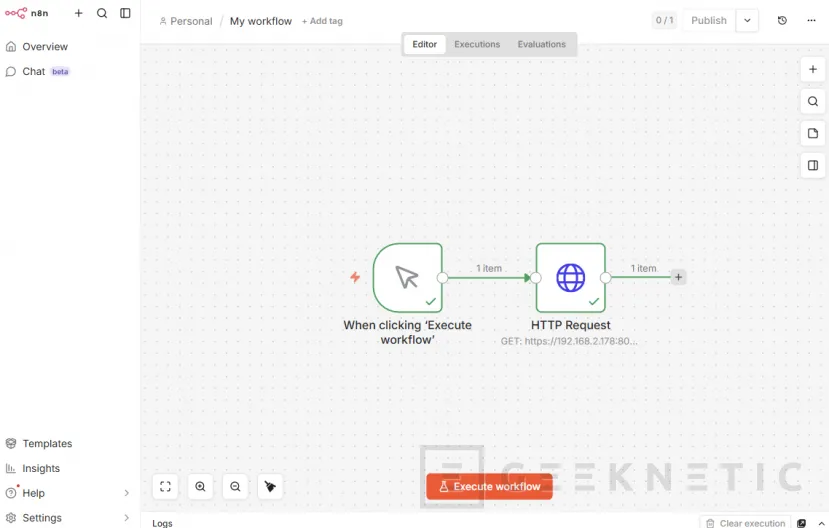
Añadir un nodo Code para separar los recursos
Ahora mismo Proxmox te devuelve todo mezclado en el campo "data".
Necesitas separar los diferentes elementos de un clúster Proxmox, así que generaremos un "Code" por cada componente:
- Nodos
- VMs
- Contenedores LXC
- Storages
Code para Recursos del Clúster Proxmox
Pulsamos el "+" del nodo HTTP Request:
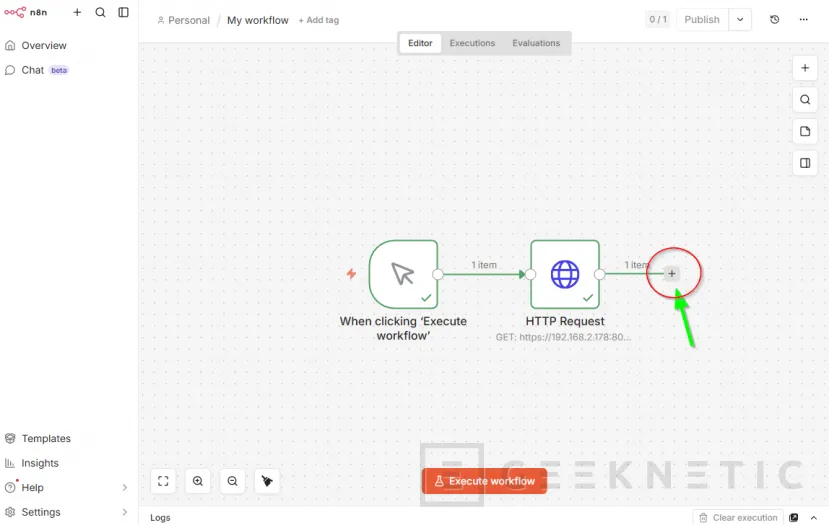
Buscamos "Code":
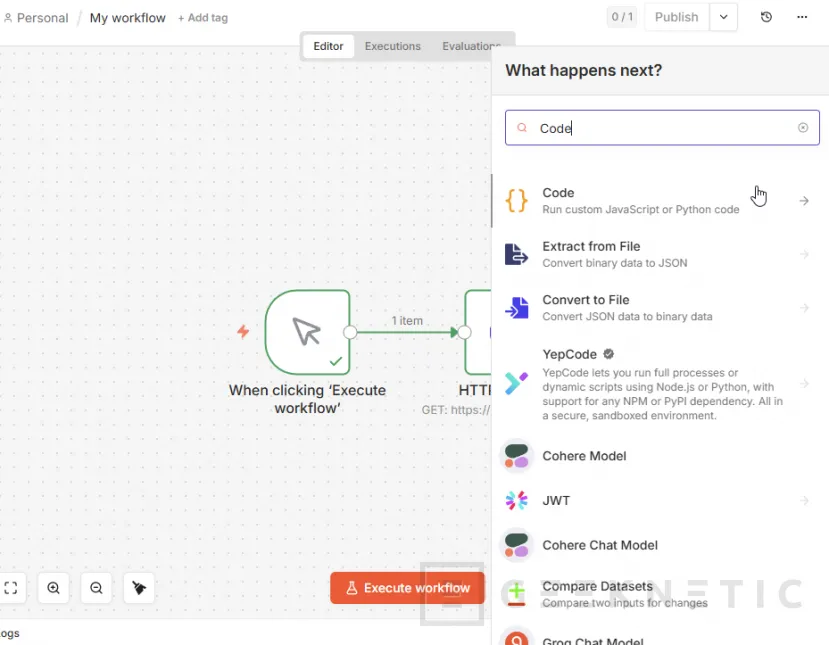
Seleccionamos "Code in Javascript":
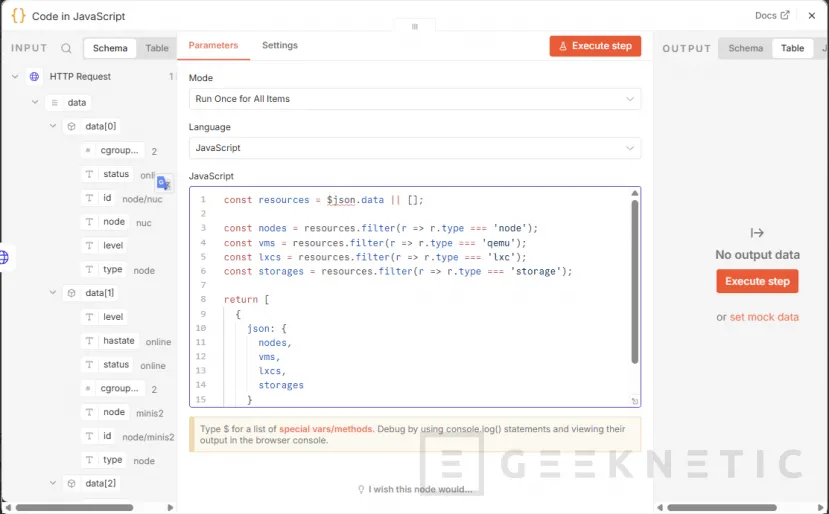
Y pegamos este código:
const resources = $json.data || [];
const nodes = resources.filter(r => r.type === 'node');
const vms = resources.filter(r => r.type === 'qemu');
const lxcs = resources.filter(r => r.type === 'lxc');
const storages = resources.filter(r => r.type === 'storage');
return [
{
json: {
nodes,
vms,
lxcs,
storages
}
}
];
Pulsamos "Execute step". Deberíamos ver la salida:
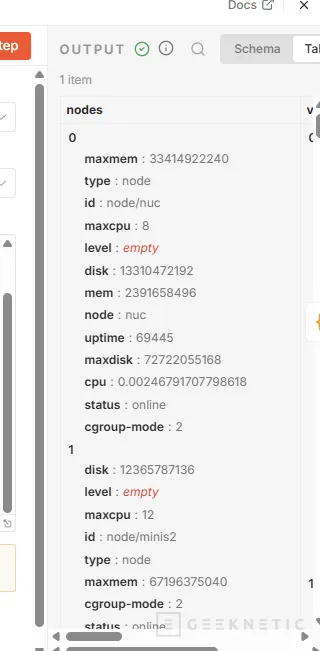
Vamos agregando recursos a revisar mediante varios códigos
Code para Nodos Proxmox
Agregamos:
const nodes = $json.nodes || [];
return nodes.map(n => ({
json: {
node_name: n.node,
status: n.status || null,
cpu_count: n.maxcpu || null,
cpu_usage: n.cpu || null,
mem_total: n.maxmem || null,
mem_used: n.mem || null,
uptime_seconds: n.uptime || null
}
}));
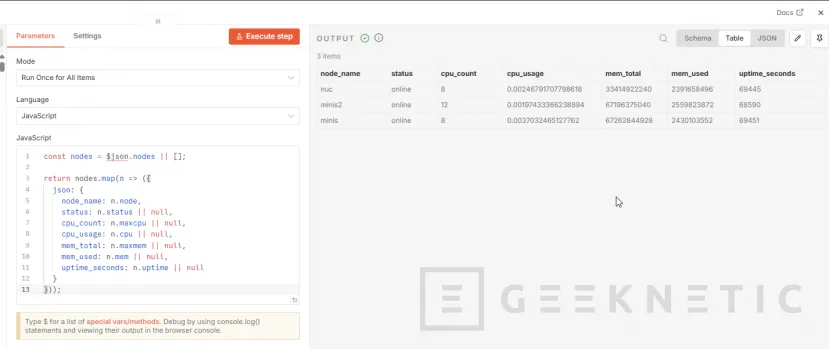
Guardamos los nodos en PostgreSQL
Añade un nodo Postgres. La documentación de n8n indica que en el nodo Postgres puedes ejecutar consultas y usar query parameters para sanitizar datos y evitar SQL injection.:
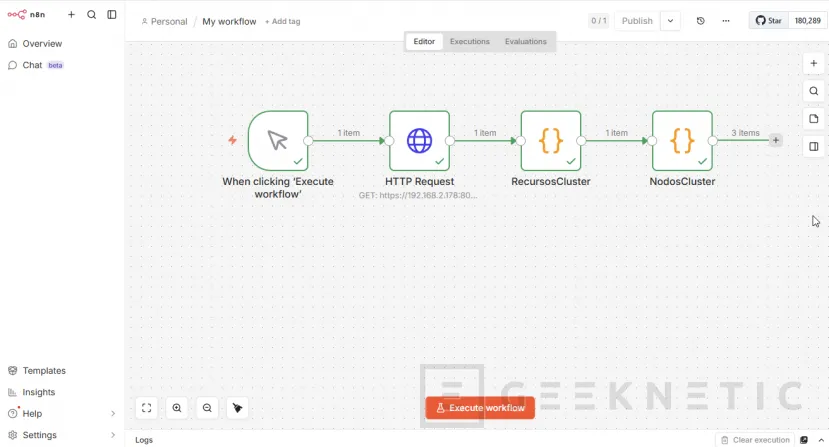
Pulsamos "+":
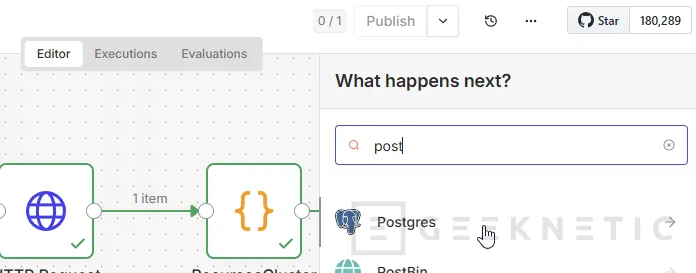
Elegimos "Execute a SQL query":
Agregamos esta query:
create schema if not exists infra;
create table if not exists infra.cluster_node (
id bigserial primary key,
node_name text not null unique,
status text,
cpu_count integer,
cpu_usage numeric(8,4),
mem_total bigint,
mem_used bigint,
uptime_seconds bigint,
last_seen_at timestamptz not null default now()
);
Si no la tenemos, deberemos crear la credencial para Postgres, si estamos en un n8n creado con Docker, será la IP del Docker Postgres, nombre de Database y las credenciales de las variables que pasamos en la instalación.:
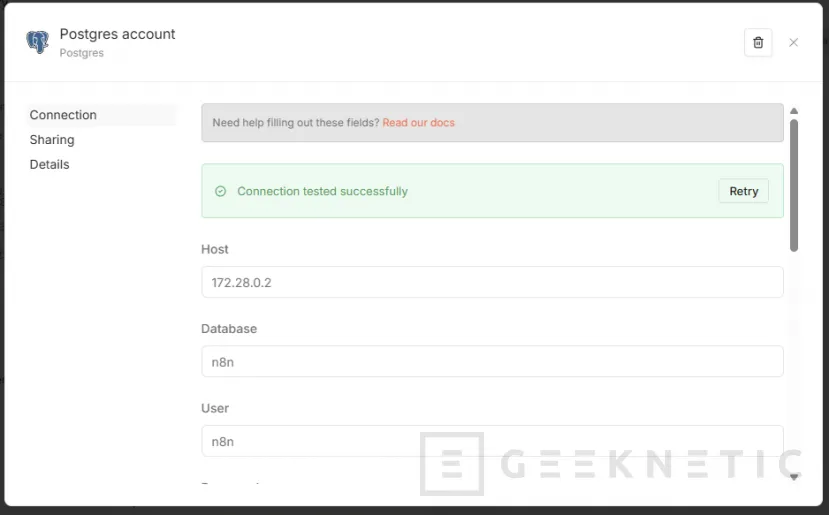
Pulsamos "Execute step":
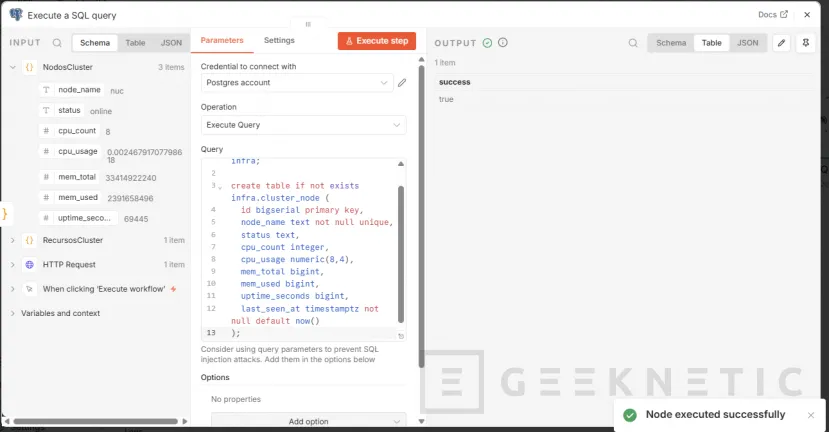
Nuestro Workflow tendrá esta pinta:
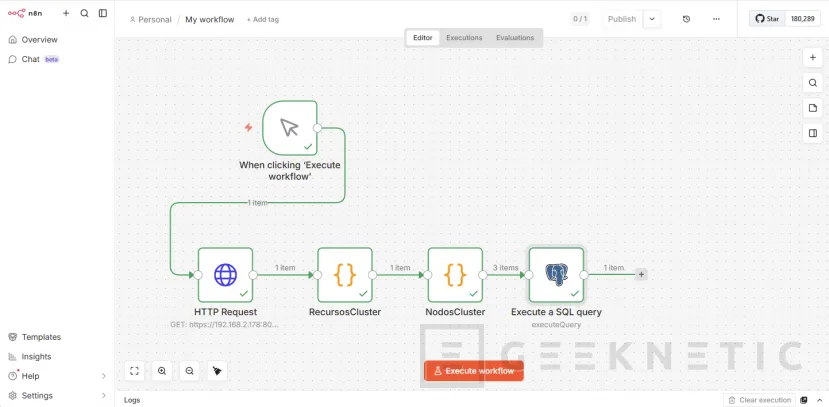
Code para VMs Proxmox
Ahora volvemos al nodo "RecursosCluster" y desde ahí creamos una nueva rama "Code" para las VMs:
Contenido Javascript:
const vms = $json.vms || [];
return vms.map(vm => ({
json: {
guest_type: 'vm',
vmid: vm.vmid,
node_name: vm.node,
name: vm.name || null,
status: vm.status || null,
cpu_usage: vm.cpu || null,
mem_used: vm.mem || null,
mem_total: vm.maxmem || null,
disk_used: vm.disk || null,
disk_total: vm.maxdisk || null
}
}));
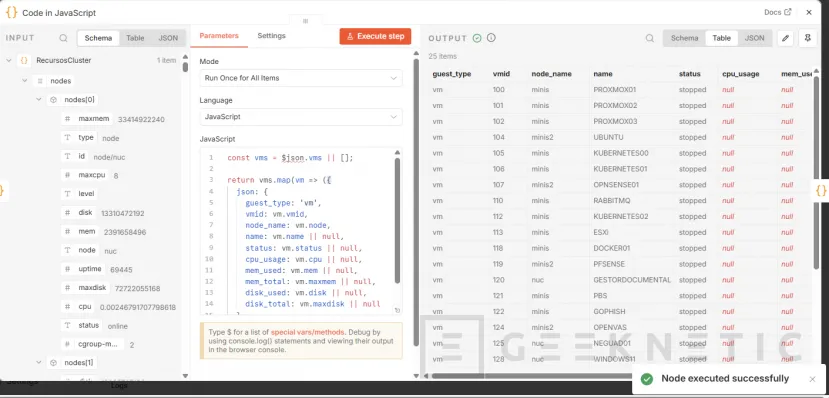
Y generamos otro nodo Postgres para VMs que crea una tabla nueva si no existe:
create schema if not exists infra;
create table if not exists infra.guest (
id bigserial primary key,
guest_type text not null,
vmid integer not null,
node_name text not null,
name text,
status text,
cpu_usage numeric(8,4),
mem_used bigint,
mem_total bigint,
disk_used bigint,
disk_total bigint,
last_seen_at timestamptz not null default now(),
unique (guest_type, vmid)
);
insert into infra.guest (
guest_type, vmid, node_name, name, status,
cpu_usage, mem_used, mem_total, disk_used, disk_total, last_seen_at
)
values (
'{{ $json.guest_type }}',
{{ $json.vmid }},
'{{ $json.node_name }}',
{{ $json.name ? "'" + $json.name.replace(/'/g, "''") + "'" : "null" }},
{{ $json.status ? "'" + $json.status.replace(/'/g, "''") + "'" : "null" }},
{{ $json.cpu_usage ?? "null" }},
{{ $json.mem_used ?? "null" }},
{{ $json.mem_total ?? "null" }},
{{ $json.disk_used ?? "null" }},
{{ $json.disk_total ?? "null" }},
now()
)
on conflict (guest_type, vmid)
do update set
node_name = excluded.node_name,
name = excluded.name,
status = excluded.status,
cpu_usage = excluded.cpu_usage,
mem_used = excluded.mem_used,
mem_total = excluded.mem_total,
disk_used = excluded.disk_used,
disk_total = excluded.disk_total,
last_seen_at = now();
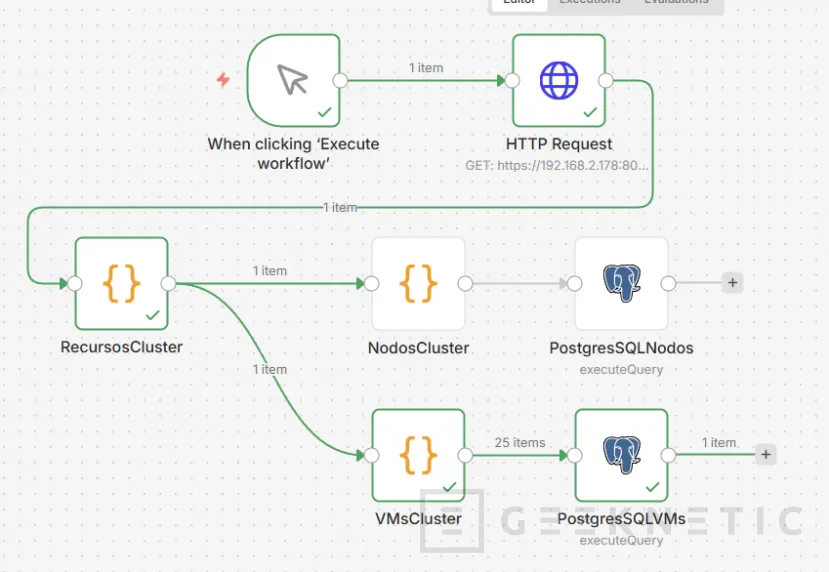
Code para LXC Proxmox
Repetimos los pasos para LXC. Un node "Code" con este contenido:
const lxcs = $json.lxcs || [];
return lxcs.map(ct => ({
json: {
guest_type: 'lxc',
vmid: ct.vmid,
node_name: ct.node,
name: ct.name || null,
status: ct.status || null,
cpu_usage: ct.cpu || null,
mem_used: ct.mem || null,
mem_total: ct.maxmem || null,
disk_used: ct.disk || null,
disk_total: ct.maxdisk || null
}
}));
Y generamos otro nodo Postgres para los LXC:
create schema if not exists infra;
create table if not exists infra.guest (
id bigserial primary key,
guest_type text not null,
vmid integer not null,
node_name text not null,
name text,
status text,
cpu_usage numeric(8,4),
mem_used bigint,
mem_total bigint,
disk_used bigint,
disk_total bigint,
last_seen_at timestamptz not null default now(),
unique (guest_type, vmid)
);
insert into infra.guest (
guest_type, vmid, node_name, name, status,
cpu_usage, mem_used, mem_total, disk_used, disk_total, last_seen_at
)
values (
'{{ $json.guest_type }}',
{{ $json.vmid }},
'{{ $json.node_name }}',
{{ $json.name ? "'" + $json.name.replace(/'/g, "''") + "'" : "null" }},
{{ $json.status ? "'" + $json.status.replace(/'/g, "''") + "'" : "null" }},
{{ $json.cpu_usage ?? "null" }},
{{ $json.mem_used ?? "null" }},
{{ $json.mem_total ?? "null" }},
{{ $json.disk_used ?? "null" }},
{{ $json.disk_total ?? "null" }},
now()
)
on conflict (guest_type, vmid)
do update set
node_name = excluded.node_name,
name = excluded.name,
status = excluded.status,
cpu_usage = excluded.cpu_usage,
mem_used = excluded.mem_used,
mem_total = excluded.mem_total,
disk_used = excluded.disk_used,
disk_total = excluded.disk_total,
last_seen_at = now();
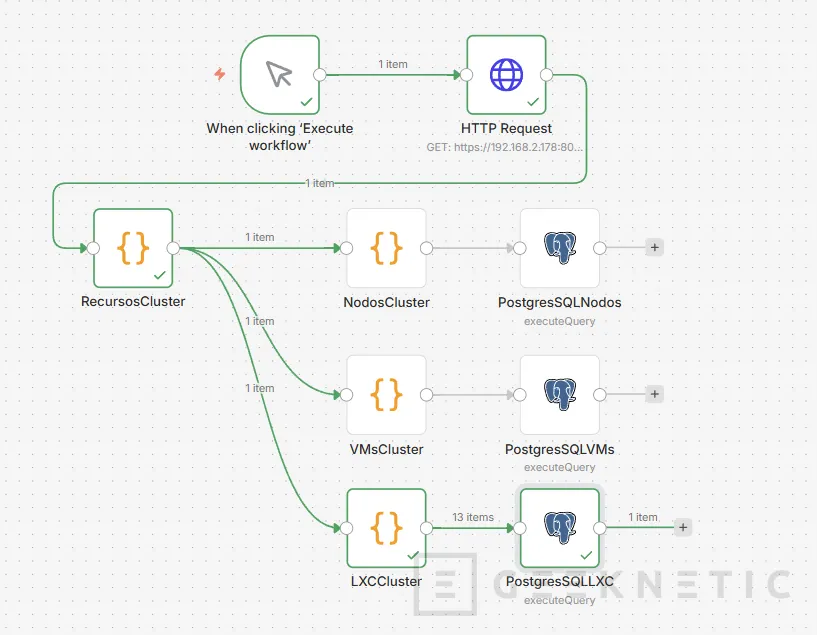
Code para Storage Proxmox
Por último otros dos nodos, un Code y otro PostgresSQLStorage:
const storages = $json.storages || [];
return storages.map(s => ({
json: {
storage_name: s.storage || null,
node_name: s.node || '',
storage_type: s.plugintype || s.type || null,
status: s.status || null,
shared: s.shared === 1 || s.shared === '1' || s.shared === true,
total_bytes: s.maxdisk || null,
used_bytes: s.disk || null,
available_bytes: (s.maxdisk != null && s.disk != null) ? (s.maxdisk - s.disk) : s.maxdisk ?? null
}
}));
Contenido Postgres:
create schema if not exists infra;
create table if not exists infra.storage (
id bigserial primary key,
storage_name text not null,
node_name text not null default '',
storage_type text,
status text,
shared boolean,
total_bytes bigint,
used_bytes bigint,
available_bytes bigint,
last_seen_at timestamptz not null default now(),
unique (storage_name, node_name)
);
insert into infra.storage (
storage_name, node_name, storage_type, status,
shared, total_bytes, used_bytes, available_bytes, last_seen_at
)
values (
'{{ $json.storage_name }}',
'{{ ($json.node_name || "").replace(/'/g, "''") }}',
{{ $json.storage_type ? "'" + $json.storage_type.replace(/'/g, "''") + "'" : "null" }},
{{ $json.status ? "'" + $json.status.replace(/'/g, "''") + "'" : "null" }},
{{ $json.shared === true ? "true" : "false" }},
{{ $json.total_bytes ?? "null" }},
{{ $json.used_bytes ?? "null" }},
{{ $json.available_bytes ?? "null" }},
now()
)
on conflict (storage_name, node_name)
do update set
storage_type = excluded.storage_type,
status = excluded.status,
shared = excluded.shared,
total_bytes = excluded.total_bytes,
used_bytes = excluded.used_bytes,
available_bytes = excluded.available_bytes,
last_seen_at = now();
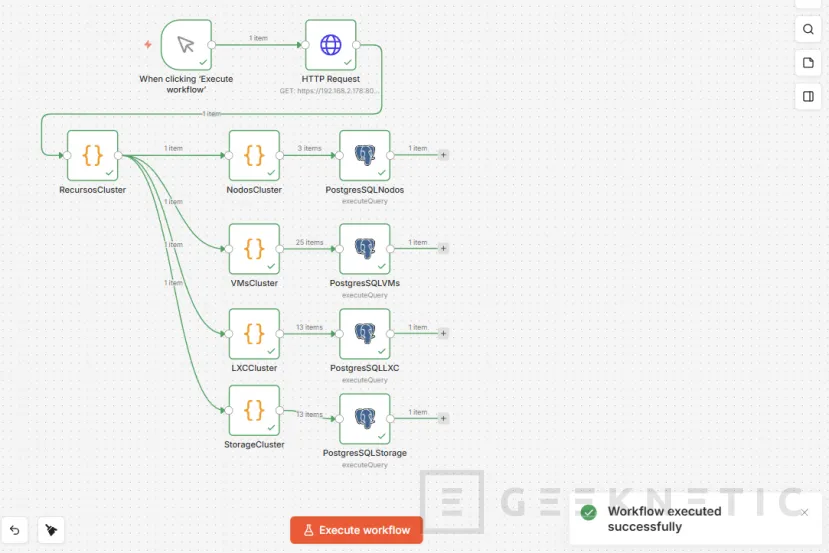
Veremos nuestro Workflow:
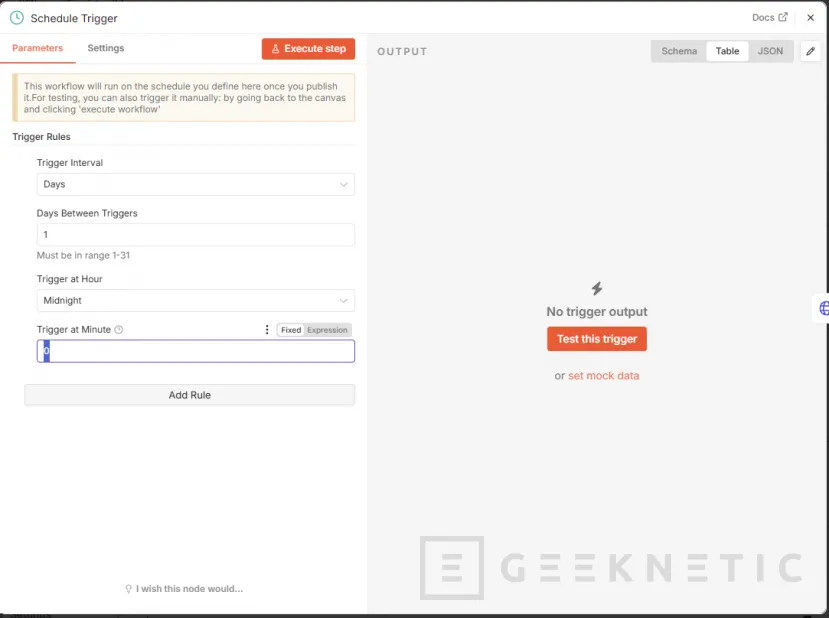
Con todo preparado, simplemente podríamos o explotar los datos, programar un Schedule Trigger o exportar a Telegram:
Automatización de Inventario con n8n
La parte difícil de un inventario no es escribir cuatro consultas ni pegar una API en n8n. La parte difícil es decidir bien qué quieres guardar, cómo lo separas y cómo evitas que el workflow se convierta en un lío imposible de mantener. Por eso merece la pena empezar por una capa base sencilla, nodos, VMs, LXC y storage.
Con ese enfoque, n8n encaja muy bien como motor de automatización. Hace la llamada a Proxmox, separa los recursos, los transforma y los deja guardados en PostgreSQL (que podrías explotar fácilmente y alimentar periódicamente) sin que tengas que ir repasando el clúster a mano cada vez. Y lo mejor es que, cuando ya tienes esa base funcionando, todo lo demás se construye mucho más fácil: snapshots, red, discos, backups, hallazgos y alertas.
Dicho de forma simple, primero montas el esqueleto, luego ya le añades músculo. Y en un inventario de infraestructura, esa forma de trabajar suele ser la diferencia entre un proyecto útil y un caos de automatizaciones que nadie quiere tocar dentro de dos semanas.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!







